Five Key Parts of the LLM Training Process
Sections
- Tokenization and Embedding
- Unsupervised/Self-Supervised Pre-training
- Supervised Fine-tuning
- Reinforcement Learning with Human Feedback
- Reasoning
This article walks through how a Large Language Model (LLM) is typically trained. Of course, there will be numerous variations and customizations among the AI companies training these models. But these are broadly speaking the general steps. Also, the description here does not cover multimodal models, which are LLMs that natively support non-text data like videos and images. However, it does include reasoning models.
Tokenization and Embedding
LLMs do not work with words like we do. Instead, they work with tokens. So, the text data is first tokenized. The tokenization process is too esoteric to be explained simply here. OpenAI’s tokenizer, tiktoken, is open source, if you want to check it out.
Tokens are also how LLMs calculate billing, but they are not very intuitive. One word does not equal one token! OpenAI has a website showing how input text is converted into tokens. For example, the figure below shows the word “strawberry” getting converted into 3 tokens. This is the reason why LLMs often fail to count the occurrence of an alphabet in a word or the number of words in a sentence!

Word embedding is one of the fundamental initial steps of the LLM training process. In the case of LLMs, we are working with tokens and not words. So, the correct term to use here is probably text embedding. The idea is to represent text/words/tokens as points in a vector space.
Then, we can use a similarity measure like Cosine similarity to quantify how similar two pieces of textual data are. The figure below, taken from Wikipedia (source), demonstrates this idea with simple examples. This embedding quantifies the notion that the words France and Germany are “close” because they are both countries. However, Paris is “even closer” to France because Paris is in France.
{kind=link}
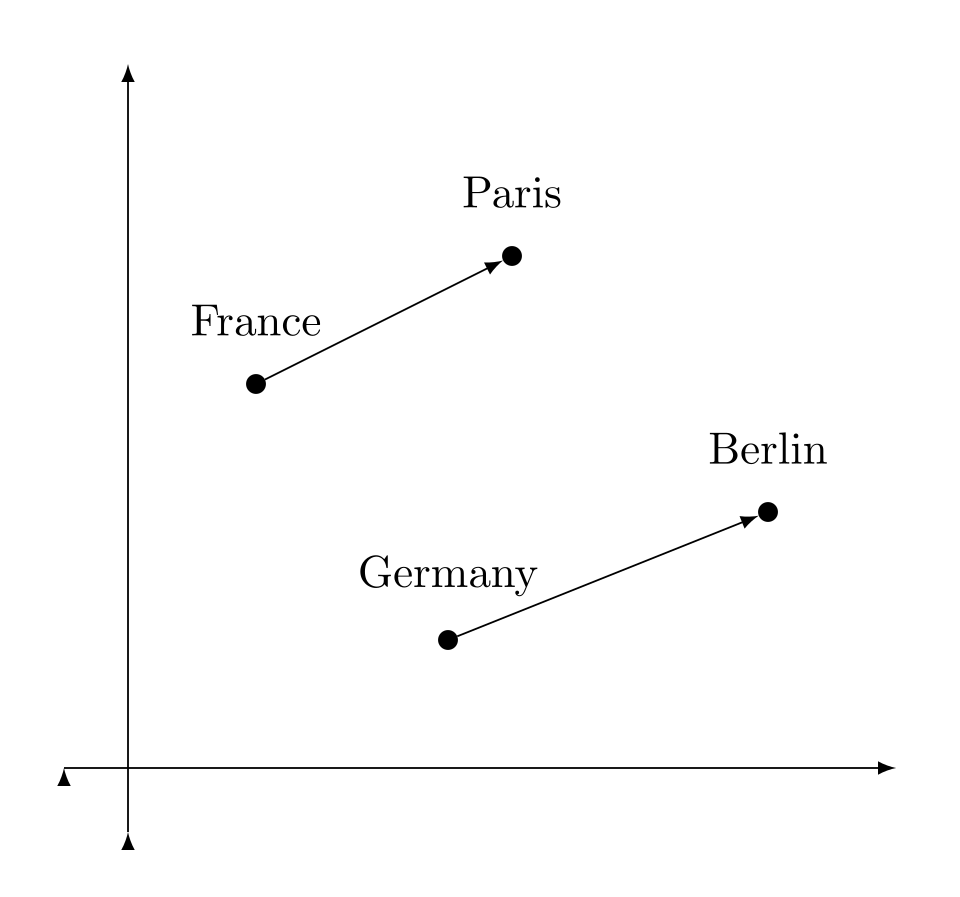
Of course, there can be a lot of variations on how different companies choose to implement tokenization and embedding. OpenAI uses its own internal embedding models, but they do offer models for text embedding as a service. Their website for this service might give you more details about how text embedding works.
Unsupervised/Self-Supervised Pre-training
Pre-training refers to training the model to do next token prediction. This means, given an input sequence of tokens or words, predict the next most likely token/word. The process is then repeated until we produce an output sequence of tokens or words.
This is not a new idea. Recurrent Neural Networks (RNNs) have been used to translate input sequences into another language this way. These are known as seq2seq models. “Seq2seq” stands for “sequence to sequence”.
The seq2seq Wikipedia page has an amazing GIF animation illustrating how a typical RNN seq2seq model translates a sequence of Chinese words into English words (source). \( e_0 \) to \( e_6 \) are words/tokens that form an input sequence. The model then generates the outputs \( d_0 \) to \( d_3 \) one word/token at a time.
{kind=link}
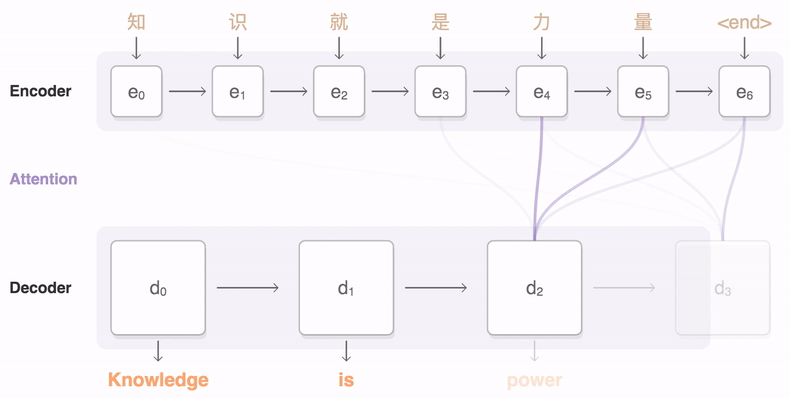
You might be thinking if the word “attention” in that image above is the same thing mentioned in the famous “Attention Is All You Need” research paper; the answer is yes! Is this step unsupervised or self-supervised? I have come across both descriptions. So, I am calling it both as well.
Supervised Fine-tuning
Just predicting the next token is not enough to produce a chatbot that sounds like a human. The model has to be trained on input-output pairs like these:
-
Input: What is Einstein’s first name?
-
Output: Einstein’s first name is Albert.
You might be thinking that this sounds like it would take a lot of human effort to produce the quantity of input-output labels required to train an LLM. You are correct! AI companies employ massive amounts of human labor to do this. A famous example is scale.ai. Their company was so successful at mass-producing these labels by hand that it was bought over by Facebook! OpenAI’s fine-tuning guide might give you more information about this supervised fine-tuning process.
Reinforcement Learning with Human Feedback
Reinforcement Learning with Human Feedback (RLHF) is yet another key step in the LLM training process.
In the early days of chatbots, many were tricked into publicly posting offensive content. The most famous example is probably Microsoft’s Tay. A lesser-known one is ScatterLab’s Luda Lee.
To prevent this from happening, companies hire masses of humans to steer their LLMs away from offensive content. For example, OpenAI is known for hiring Kenyan workers to label anything that is deemed toxic.
Unfortunately, not much concrete/technical has been made public about this step in the training process, as far as I know.
Reasoning
Around late 2024, it became apparent that LLMs have trouble scaling due to running out of good training data. See this article for an example of what journalists were saying during that time.
AI companies converged on the solution of turning their LLMs into reasoning models. However, “reasoning” is a misnomer, as these models cannot be said to do any actual reasoning. Roughly speaking, these are the two steps that these models perform during “reasoning”.
-
Chain of Thought: asking the model to produce its output step by step. This might involve asking the model to repeat/check its output.
-
Reinforcement Learning: training the model to perform chain of thought optimally.
While it is impressive that they were able to achieve performance improvements with this, there were some severe drawbacks.
-
Reasoning models were much more expensive simply because more computations are done and more output tokens are produced.
-
The reinforcement learning step really only works for questions with definite answers. This is why most of the improvements are in mathematics and programming tasks.
-
The reasoning framework often breaks in practice, especially when the question has vague or no answers. For example, I have seen reports of reasoning models taking 10+ minutes to respond to just a simple “hello”.
The team behind the famous DeepSeek open-source LLM model published a paper on LLM reasoning that might give you more information regarding reasoning.