Feedforward Neural Networks Part 1 - The Perceptron
In this series of article, I will briefly go through key topics relevant to feedforward neural networks. Despite how simple the architecture of feedforward neural networks are when compared to more advanced models like Part 1 will focus on the relatively simple but still interesting perceptron, which is a pivotal part of the invention of modern artificial neural networks.
History of the Perceptron
The current AI craze surrounding neural networks started with a pair of papers. However, I have seen various places cite one but not the other.
-
McCulloch and Pitts 1943 - “A Logical Calculus of Ideas Immanent in Nervous Activity”
-
Rosenblatt 1957 - “The Perceptron — A Perceiving and Recognizing Automaton”
Rosenblatt’s original paper on the perceptron is actually a typewritten report that is not the easiest to read. But thankfully the author wrote a “nicer” version a year later.
- Rosenblatt 1958 - “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain”
XOR and AI Winter
Another interesting fact about the history of the perceptron is that Marvin Minsky and Seymour Papert’s book, titled “Perceptrons”, is often mentioned as being responsible for causing an “AI Winter” in 1969. One fact that we will use extensively in the next sections is that the perceptron requires the data in the binary classification problem to be linearly separable. There are many examples of data that is not linearly separable, like the infamous exclusive or (XOR) relation. Limits like this highlighted by the book is supposedly what caused a sudden drop in AI research. However, I am sure the story isn’t that simple!
Separating Hyperplane
I will roughly follow Killian Weinberger’s Cornell lectures but there will be some minor differences in notation.
Suppose we have a set of training data points $ \{ (x_i, y_i) \} $ for a binary classification task. The $ x_i $ are vectors, and $ y_i \in \{ -1,1 \} $ . The perceptron constructs a classifier
A key assumption of the model is that the $ y_j = -1 $ and $ y_k = 1 $ points can be separated geometrically with a hyperplane. Technically the hyperplan is $ w^t x_i + b $ but the “bias” term $ b $ can be eliminated using the trick of adding a constant $ 1 $ to the end of the feature vector $ x_i $ and adding a constant $ b$ to the end of the hyperplane normal vector $ w $ . This process increases the dimension of the feature space by one.
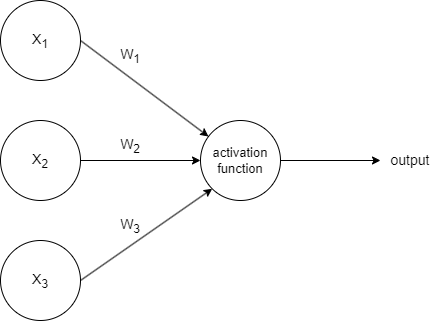
The figure above is a visual representation of a perceptron. Readers who are more familiar with how neural networks are represented visually will recognize that this is exactly how a simple feedforward neural network with no hidden layers looks like. The activation function here is simply the $ h_i $ defined above.
Perceptron Convergence Theorem
From what I understand, the original author Rosenblatt also gave an algorithm for training a perceptron on a linearly separable dataset. However, the one I am describing below comes from Killian Weinberger’s Cornell lectures.
-
Initialize the hyperplane normal vector $ w = 0$ .
-
Loop through all data points. If a point $ x_i $ is misclassified, set $ w = w + y_i x_i$ .
-
Repeat until no more points are misclassified. Note that $ w^t x_i = 0 $ needs to be considered misclassified.
It is surprisingly that this extremely simple algorithm converges and this fact was mathematically proven in Novikoff 1963. Note that the theorem says the algorithm would converge to a solution, but there is no telling which solution it actually converges to. The proof is truly a beautiful work of art and very enjoyable to go through. I highly recommend watching Killian Weinberger’s lecture on it.
Here is the trickiest part and key insight to the proof:
- We first assume that the algorithm converges to a separating hyperplane with normal vector $ || w^*|| \leq 1 $ .
This to me is the craziest part of the proof. In order to prove that the algorithm converges, we assume that there is solution that it converges to! Then, the rest of the proof boils down to essentially three key steps:
-
All feature vectors $ ||x_i|| \leq 1 $ . i.e. They are all within the unit circle.
-
Let $ \gamma = min_{(x_i,y_i)} |x_i^T w^*| $ be the margin of the hyperplane. This is the minimum distance from a feature vector to the hyperplane.
-
Interesting, it can be shown that after $M$ updates, $||w^T w|| <= M $ and $||w^T w^*|| >= M \gamma $ .
The definition of the inner product and the inequalities in the third point can be used to show that $ M \leq \frac{1}{\gamma^2} $. This is yet another mind bending part of the proof: we started with an arbitrary $ M $ number of update steps, then show that the number of update steps must be bounded above by $ \frac{1}{\gamma^2} $!
Note that $ \frac{1}{\gamma^2} $ decreases as the minimum margin $ \gamma $. increases. This means that the algorithm converges faster for datasets with $ -1 $ and $ 1 $ points that are further apart.
Comparison to Logistic Regression
For binary classification, both the perceptron and logistic regression are trying to do the same thing: find a linear separator for the data. There are two key differences.
Activation Function
Both the perceptron and logistic regression can be seen as doing the same thing, but with different loss functions. This is succinctly stated in the chapter 19 summary section of the famous textbook “Artificial Intelligence: A Modern Apporach, 4th Edition”:
Logistic regression replaces the perceptron’s hard threshold with a soft threshold defined by a logistic function.
The input to both model’s activation functions is a linear combination of the features $ w^t x $. This set of lecture notes explicitly work through the mathematics of viewing both models as minimizing their respective loss function.
Model Fitting and Separability Assumption
The perceptron is fitted using an algorithm that requires a separating hyperplane to exist and hence the data must be linearly separable. Logisitic regression is fitted using maximum likelihood and does not require the data to be linearly separable.
Perceptron in PyTorch
In this last section, I will quickly code up a perceptron in PyTorch on mock data and illustrate the resulting separating hyperplane.
Work in progress.